谢海华,陈志优,程 静,吕肖庆,2,汤 帜,2
(1. 北大方正信息产业集团有限公司 数字出版技术国家重点实验室,北京 100871;
2. 北京大学 王选计算机研究所,北京 100871;
3. 北京雁栖湖应用数学研究院,北京 101408)
中文语法错误检测(Chinese Grammatical Error Diagnosis,CGED)的目标是自动检测出中文自然语句中的语法错误,如成分缺失或多余,语序不当等。CGED的检测任务一般包含:
是否存在错误、错误类型及错误发生位置。虽然CGED不能给出纠正错误的建议,但对于辅助写作和文档审校等场景依然十分有意义。在辅助写作中,CGED给出语法错误类型和位置,让作者有针对性地修改文章,可以提升写作的质量和效率。另外,在出版行业的审校环节,由于正式出版物的格式要求十分严格,CGED可自动检测出一些基础的语法错误,可以为审校人员节省大量的时间,而直接纠正语法错误则可能造成文章的内容和逻辑发生变化。
目前,有关语法错误检测的研究大多数是针对英文的。与英文相比,中文的语法更加复杂和灵活。中文不存在词语的单复数和时态等明确的语法规则,其语法错误经常涉及隐晦的语义解析,不能基于字词形态来判断。[1]因此,现有的英文语法错误检测方法不能很好地适用于CGED。另外,目前研究者倾向于运用生成式的方法直接进行语法改错,跳过了语法错误检测的步骤[2-4],只有少量的研究采用序列标注方法进行中文语法错误检测。然而,由于缺乏大规模高质量的标注语料作为训练集,CGED的准确率往往不高,达不到实用水平。如何在训练数据有限的情况下提高语法错误检测的效果是该类研究的一个难点。
针对上述问题,本文提出一种基于数据增强和语言学特征多任务训练方法来提升中文语法错误检测的效果。针对训练语料不充足的问题,本研究使用大量无标签的正确中文语料,通过词性规则、句法规则以及语言模型概率统计等方法来生成接近真实语法错误用例的样本,以扩充训练语料。此外,本研究采用预训练语言模型对字词进行表征,以利用大规模语料蕴含的语义信息,并将词法学习、句法学习、语法错误检测等任务结合起来进行多任务学习,进一步获取中文语义和语法信息。本文提出的方法在NLPTEA CGED评测任务数据集上进行测试,准确率和召回率分别为85.16%和72.53%(F1值为0.783),性能优于其他对比检测模型。
中文语法错误自动检测模型采取的方法从最初的统计学习方法[5]和基于规则的分析[6],到现在主流的深度学习算法[1,7],以及多种模型混合的方法[8]。大多数研究采用序列标注模型来进行语法错误检测,并使用LSTM和CRF来实现[1,7,9]。使用LSTM模型进行语法错误检测时,特征的选择十分重要,除了通常使用的字向量特征、词向量特征、词性POS特征,很多研究提出了许多新的特征[1,8-9]。例如,高斯互信息(ePMI)、向量词的共现(AWC)、依赖关系词语的共现(DWC)、基于语境的词表达等。也有一些研究针对LSTM模型结构进行改进,比如在LSTM模型中加入策略梯度[10]。这些研究的重点在于学习中文语法规律,基于无标注语料统计词语规律和词语用法,并提出相应的特征来提高检测效果。然而,统计特征不能捕获深层的语法和语义信息,因此无法发现一些隐晦的语法错误。
针对训练语料不足的问题,一些研究者使用未标注的中文语料来构造错误用例。例如,通过随机增加、删除、替换字词和打乱字词顺序来生成错误样本[11];
统计已有训练语料中语法错误分布,并构造相应的错误样本[12]。前者采用随机方式构造的语法错误样本,往往显得不够真实,其语法错误分布与正常写作者所犯错误的分布相差较大。而后者构造的错误数据过于拟合已有的训练样本,不利于模型的泛化。
近年来,一些学者利用基于大规模语料预训练的语言模型来获取文本的语言学特征,以弥补训练语料的不足。基于预训练语言模型的语法错误检测模型,其效果优于通过融合多种特征构建的模型[13-14]。不过这些方法都以英文为研究对象,它们尚未在中文数据集上进行试验或者测试性能。
大多数情况下,语法错误检测的目的是对语法错误进行纠正。在检测出语法错误的类型和发生位置之后,可以根据错误类型,采用相应的方法来修改语法错误。例如,错误提示为“成分冗余”,则直接删除该成分;
错误提示为“用词不当”,则基于词语统计信息(如PMI)推荐候选词语以替换错误词语[1,12]。不过目前中文语法错误纠正的研究大多采用端到端的生成式方法,使用统计翻译模型[2]、深度学习模型[3]、融合规则和统计的算法[4]等,由错误句子直接生成正确的句子。但是生成的句子有时会改变原文的表达方式甚至语义和逻辑,在很多情况下不能产生令人满意的结果。
这一节将详细介绍本文提出的语法错误检测模型APM-CGED(APM代表data Augnentation,Pre-trained language model and Multi-tasklearning),其系统框架如图1所示。为了解决训练语料缺乏的问题,本文采用数据增强方法来扩充训练数据集,使用预训练语言模型BERT[15]作为基础的文本表征提取工具,并运用多任务训练数据来调整BERT参数以使它学习到更多的语言学特征。

图1 APM-CGED系统框架
本文主要贡献是提出了基于句法分析与预训练语言模型采样的数据增强方法和基于语言学特征多任务学习的模型优化方法。以下将对图1所示流程和上述两项贡献进行详细阐述。
2.1 基于句法分析与预训练语言模型采样的数据增强(构造训练数据)
中文语法错误检测研究的主要问题之一是训练语料的缺乏。我们使用大量未经标注的正确语句构造含有语法错误的训练样例,以弥补训练数据不足的问题。中文维基百科覆盖面广且表达方式丰富,人民日报表达方式规整规范,所以我们以维基百科和人民日报中文数据集为基础,抽取其中正确的语句,并对数据进行处理后构造训练样本。主要步骤的介绍如下。
2.1.1 数据集预处理
主要的处理手段如下:
(1) 增加数据的一致性和减少噪声,例如,将中文维基百科的繁体中文转化成简体中文,把全角字符转化为半角字符。
(2) 运用中文处理工具对文本进行分词、词性标注、命名实体识别和依存句法分析。
(3) 选择质量较高的句子,例如,去除过长(词数超过100个)和过短(词数小于3个)的句子。
2.1.2 错误样例构造
本步骤将一些正确的语句改造为含有语法错误的语句。在语句经过分词、词性标注和依存句法分析之后,我们采用以下措施,构建不同类型的语法错误的训练样本。
(1) 成分冗余构造:
在语句的词语之间随机插入没有实际意义的词语。候选的插入词语选自停用词表。
(2) 成分缺失构造:
从主谓结构片段中删除主语或者谓语,从动宾结构片段中删除谓语或者宾语,从状中结构或者定中结构片段中删除被修饰成分。
(3) 语序不当构造:
修改动宾结构、状中结构、定中结构等结构片段中成分的顺序。
(4) 用词不当构造:
随机选取一个词语并将其遮盖(用MASK将其替换),然后用BERT的Masked LM预测出的候选字替换原来的字符。
2.1.3 错误样例构造规则
为了保证改造后的句子在含有语法错误的同时,保持语句的基本语义和结构,以免发生意思改变,我们设计了以下规则。
(1) 不对命名实体进行修改。命名实体在句子中往往是主体成分,修改命名实体会改变句子的意思。例如,句子“协和医院是中国最好的医院之一,专治各种疑难杂症”,如果对“协和医院”进行修改,语句的意思就会发生变化。
(2) 对于短句子,我们构造的样例中只含有一个错误。对于15个词语以上的句子,我们会随机增加错误。
(3) 在成分缺失和语序不当构造时,避免修改依赖距离很远的结构成分,防止破坏语句结构。
(4) 关于用词不当构造,除了构造“的、地、得”之间的误用情况,不对虚词、语气词之类无意义的词语进行修改以构造该类错误。实际样例中,虚词的使用错误主要是成分缺失和冗余。
以下是两个构造的错误样例示例。
样例一:
语序不当构造
原句:加速推广菌草技术,将其列入国家开发计划。
构造句:推广加速菌草技术,将其列入国家开发计划。
样例二:
用词不当构造
原句:
我跟朋友们经常用手机打电话聊天。
构造句:
我跟朋友们经常用手机找电话聊天。
2.2 基于语言学特征多任务学习的模型优化
在以往的CGED研究中,研究者使用的主流模型是BiLSTM-CRF结构。由于中文语法错误的复杂性和多样性,语法的正确使用与语言学特征高度相关,因此使用少量的训练数据很难训练出一个鲁棒性好的CGED模型,人们会在模型中加入词性、N-gram、PMI等语言学特征。但是,大量特征的使用使得模型结构烦琐,而且提取这些特征信息也大大降低了模型的运行速度。
本文采用基于BERT的预训练语言模型作为基础来构建CGED模型,利用它们在预训练阶段学习到的深层语义信息。然后,我们采取多任务学习方式对BERT的参数进行调整,使模型学习到各种语言学知识,并在预测阶段不必进行语言学特征提取,以提高模型的性能和效率。
多任务学习是指为模型设置多个训练目标,这些任务之间具有一定关联,并在训练阶段可以互相促进以达到更好的训练效果。多任务学习通过在模型上设置一些共享参数来实现。本文提出的方法使用BERT作为模型的共享部分,并使用不同结构来实现词性标注、依存句法分析和语法错误检测三个具体任务。基于语言学特征的多任务学习进行BERT模型优化的结构如图2所示。

图2 基于语言学特征的多任务学习模型
在图2所示的模型的输出目标中,主要包括:
词性标注,依存句法分析和语法错误检测。基于这三项任务的训练,可以对BERT的参数进行优化,以使BERT能学到更多的语言学知识。我们认为,这三个任务之间有互相促进的作用,词性和句法分析的结果能辅助判断语句是否有语法错误。例如图2中的例句“爱我北京天安门”是一个语法错误句,它的词性标注结果是:
动词-代词-名词,这个词性序列在中文语句中不常见,因此该句很可能含有语法错误。同样地,判断出语句含有语法错误,也有益于更准确地分析语句的词性和句法。这三个任务的详细描述如下。
2.2.1 词性标注
我们采用序列标注方法来实现词性标注任务,在BERT之后增加一个全连接层直接输出词性结果。由于BERT采用字符嵌入方式,对于多字符词语,我们采用“BI”的标注方式(‘B’表示词语开始位置,‘I’表示词语中间或结束位置)进行词性标注。在准备训练数据时,词性标注的标签可以由中文处理工具(例如pyltp[16])直接生成,标注示例如表1所示。

表1 词性标注示例
2.2.2 依存句法分析
依存句法分析的目的是确定语句的句法结构,通常以句法树的形式,用有向弧表示词语之间的修饰及指向关系(即依存关系)。在本文中,我们将句法结构(或词语之间的依存关系)用矩阵形式来表示。对于一个含有n个字的句子,用一个n×n的矩阵表达词语之间的依存关系。为了避免关系矩阵(记为M)过于稀疏,我们将依存关系进行简化,取消修饰词和被修饰词之间的指向关系,所以M是一个对称矩阵。假设语句的第i个词(含有一个字符,在句子中的序号设为wi)与第j个词(含有三个字符,在句子中的序号分别为wj1,wj2,wj3)之间的关系为动宾关系(VOB),则有Mwiwj1=Mwiwj2=Mwiwj3=VOB,而且Mwj1wi=Mwj2wi=Mwj3wi=VOB。我们将语句的主干词对应的对角线位置的值设置为Head,而对角线上其他位置的值设为0。以矩阵表示的句法结构示例如图3所示。

图3 依存句法结构矩阵示例
在准备训练数据时,语句的句法结构矩阵可以由中文处理工具生成的句法树修改而成。在参数优化阶段,假设输入语句为S,其文本序列长度为t,经过BERT之后的语义表征为SBERT,它的维度为t×768。然后采用式(1)产生两个中间变量H1和H2。
f表示对矩阵进行形变操作的函数,Wi和bi是随机初始化并在训练中更新的参数。产生的H1和H2的维度都是64 ×t×12。然后基于式(2)产生句法结构分析结果。
M的维度64 ×t×t,对应t×t矩阵的每个元素的数值(维度是1 ×64),即句法结构矩阵的结果。
2.2.3 语法错误检测
我们采用多标签分类的方法完成语法错误检测任务,在BERT之后增加一个全连接层直接输出分类结果。分类的结果是句子含有的语法错误的类型。如果语句不含语法错误则输出“没有错误”,如果它含有多个语法错误则输出多个语法错误标签。语法错误检测的训练数据是由前文所述方法构造出来的或者是在实际写作中产生的。
上述三个任务模型的损失函数都用交叉熵来计算。多任务学习模型的损失函数是这三个模型的损失函数之和,模型训练的目标是最小化该损失函数。
2.3 基于序列标注的CGED模型训练和应用

图4 中文语法错误检测模型
我们把CGED视为序列标注问题,并选用BERT-CRF结构作为模型的基本架构,其中BERT的参数经过2.2节所述方法进行调整,见图4。由于我们处理的对象是中文数据,我们使用中文BERT模型,它是基于大量中文维基百科语料预训练而成。在BERT之后使用CRF模型[17],一种经典的序列标注方法,直接生成语法错误检测的结果。语法错误标签使用“BIO”方式编码,“B”代表错误的开始位置,“I”表示中间或者结束位置,“O”表示当前字符没有语法问题。例如对于错误X,“B-X”代表“X”错误的第一个位置,“I-X”表示其他位置。
在训练阶段,训练数据集的部分数据来自人们在实际写作中出现的语法错误,而另一部分则来自前文所述方法构造出的数据。训练模型和预测模型的结构是一样的,输出的结果包含是否存在错误、错误类型以及错误发生的位置。
我们采用NLPTEA中文语法错误检测评测数据集[18]试验了我们的方法。NLPTEA提供一份标注过的语法错误数据集,语料来源是汉语非母语的汉语学习者在中文写作中产生的错误样例。该数据集将语法错误分为四种类型:
redundant errors(记为‘R’,即成分冗余),missing words(记为‘M’,即成分缺失), word selection errors(记为‘S’,即用词不当)和word ordering errors(记为‘W’,即词序不当)。数据集里的语句可能没有语法错误,也可能含有一个或多个语法错误。语法错误检测系统需要从以下三个方面对语句进行检测:
(1) Detection-level:
检测语句是否含有语法错误。
(2) Identification-level:
语句含有的语法错误的类型。
(3) Position-level:
语句含有的语法错误的位置。
3.1 数据收集和处理
我们使用pyltp中文处理工具对语句进行分词、词性标注和依存句法分析,同时采用pyltp的标注体系。在多任务学习优化BERT时,我们使用了一些公开数据集来提升分词的准确性,以提高词性标注和依存句法分析的准确度。
我们收集了NLPTEA 2016,IJCNLP 2017和NLPTEA 2018的CGED任务的评测数据集,有语句数量为20 451,按照句号、问号和感叹号拆分之后的语句数量为104 141。选择其中80%的数据作为训练数据,其余数据为校验数据。同时,我们收集和整理了中文维基百科数据集和人民日报数据集,使用2.1节介绍的数据构造方法生成训练数据(语句总数为138 825)并加入到训练集。为了维持正确语句和错误语句的比例,我们在数据集中加入了同等数量的不含语法错误的语句。
3.2 实验结果
我们按照2.2节介绍的方法,运用训练数据对BERT的参数进行调整。然后使用训练数据对语法错误检测的BERT+CRF模型进行训练,使用校验数据进行测试。我们同时使用不同的模型进行了对比实验,表2显示了对比实验的结果。其中,B0表示未经过优化的BERT模型,MTL表示多任务学习方法,DA表示数据增强,B0+MTL+DA则表示文本采用的方法。不同的模型分别在NLPTEA 2018 CGED任务的HSK测试集(NLPTEA-18-HSK)、NLPTEA 2016 CGED任务的HSK测试集(NLPTEA-16-HSK)和TOCFL(NLPTEA-16-TOCFL)测试集上进行了实验。
对比实验结果表明,使用语言学特征对BERT进行优化之后,语法错误检测的效果在各方面都有明显的提升,特别是检测的召回率得到很大提高。但是随着召回率的上升,检测精确率有一定程度的下降,不过数据增强的使用很好地弥补了这个问题,使得模型能够同时提高检测的召回率和精确率,并使F1指标提升。

表2 中文语法错误检测模型的对比实验结果
我们与NLPTEA 2018 CGED评测结果进行了横向对比。我们没有采用模型融合以进一步提高检测效果,只用单一模型来与NLPTEA 2018评测效果较好的模型进行对比,结果见表3。HFL、CMMC-BDRC和NCYU是NLPTEA 2018评测结果里面准确率、召回率或者F1值较高的模型。在Detection Level和Identification Level这两个测试指标上,我们的单模型都取得了最优的F1值。但是在Position Level指标上,我们方法的效果不如HFL。经过分析,我们认为这可能是因为构造的错误案例与实际测试的错误案例错误分布不一致而造成的。
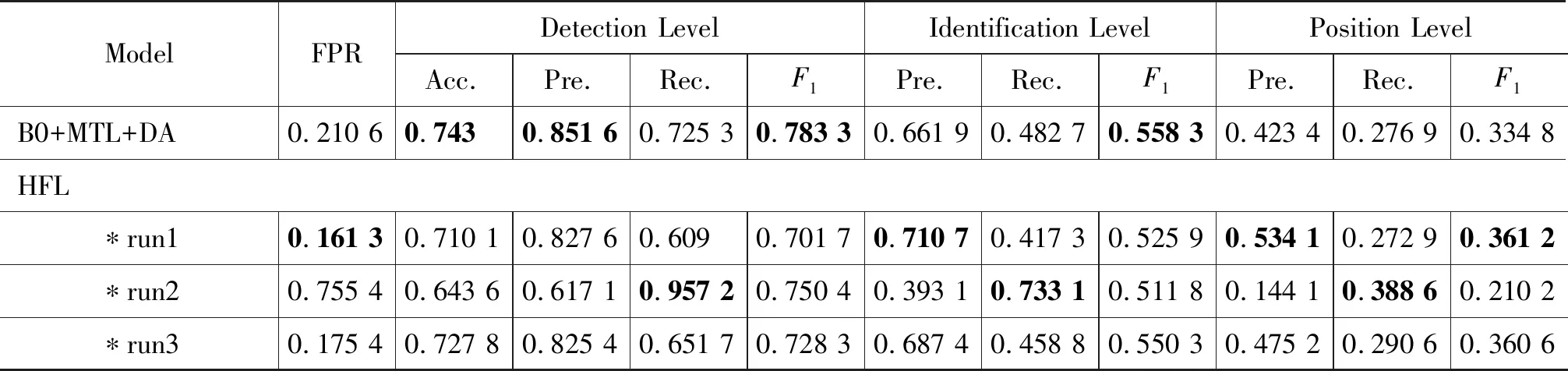
表3 BERT+MTL+DA与NLPTEA 2018 CGED评测模型的对比

续表
本文针对中文语法错误检测研究存在的主要问题之一是训练语料的缺乏,采用数据增强、预训练语言模型和语言学特征多任务学习的方式,有效地提高了语法错误检测的效果。使用语言学特征对语言模型进行优化能够使它学习到显式的语言学特征以及隐藏的语义信息,而语言学特征和语法使用是十分相关的,所以它对语法错误检测效果有明显的改善作用。
由于中文语法的复杂性,我们目前的工作依然存在很多不足,错误类型和位置的检测效果不好。在下一步的工作中,我们将进一步提高数据构造的合理性,使构造的错误样本更符合人们实际所犯的语法错误。另外,我们会对语言学特征的多任务学习的结构进行改善,以进一步提高CGED任务的检测效果。
猜你喜欢 语法错误语料语句 基于归一化点向互信息的低资源平行语料过滤方法*通信技术(2021年12期)2022-01-25重点:语句衔接新世纪智能(语文备考)(2020年4期)2020-07-25汉语负迁移对英语写作的影响及启示科技资讯(2016年25期)2016-12-27高中英语写作中的语法错误分析青春岁月(2016年22期)2016-12-23《苗防备览》中的湘西语料民族古籍研究(2014年0期)2014-10-27我喜欢小学生·多元智能大王(2014年6期)2014-07-09国内外语用学实证研究比较:语料类型与收集方法外语教学理论与实践(2014年2期)2014-06-21基于统计的中文词法分析应用">异种语料融合方法:基于统计的中文词法分析应用中文信息学报(2012年2期)2012-06-29作文语句实录小雪花·初中高分作文(2009年8期)2009-11-16